Have you ever wondered how Google translates an entire web page into a different language in just a few seconds? Or how does your phone gallery group images based on their location? All of this is possible thanks to deep learning algorithms. But what exactly is deep learning?
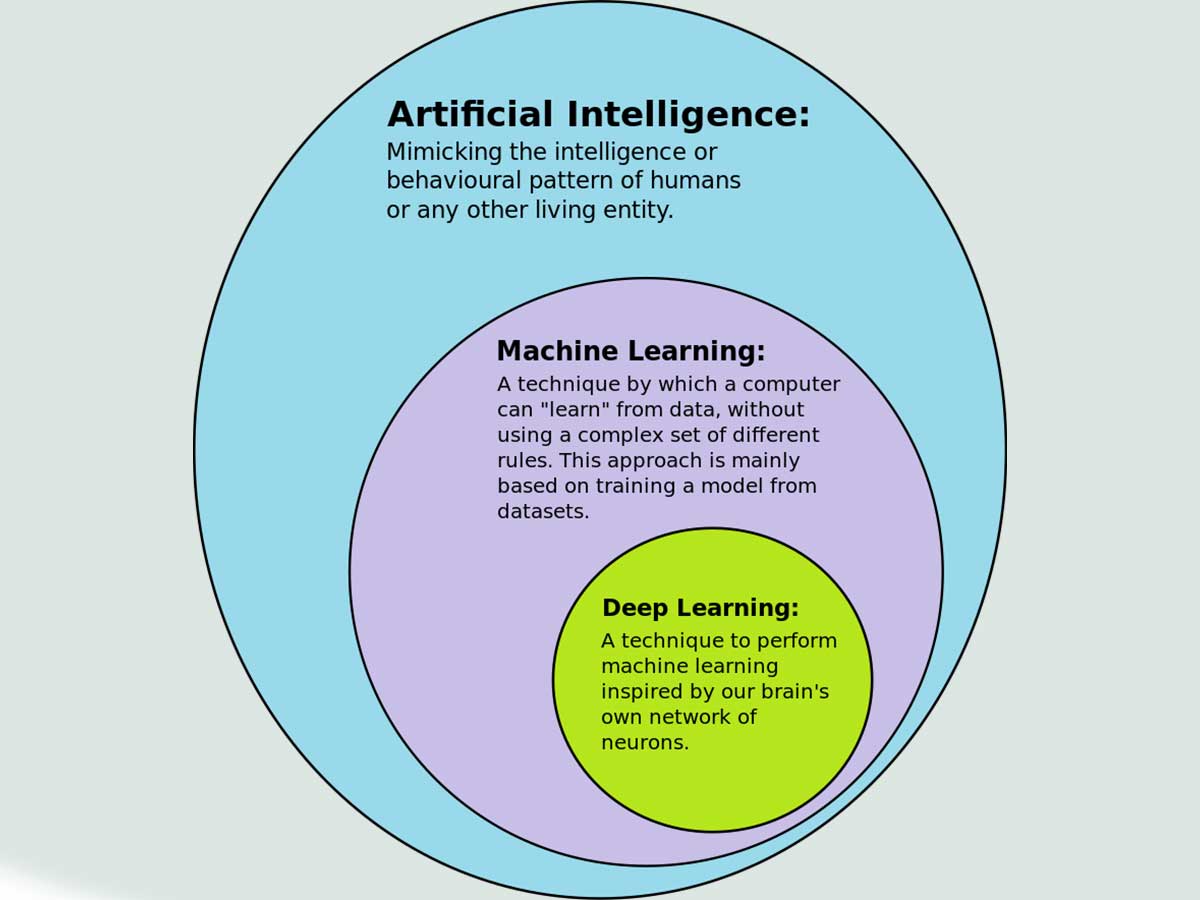
Deep learning is a subset of machine learning, which itself is a subset of AI (artificial intelligence). AI is a technique that enables a machine to mimic human behavior. Machine learning is a method of achieving this through algorithms trained with large amounts of data.
Deep learning, specifically, is a type of machine learning inspired by the structure of the human brain. In terms of deep learning, this structure is called neural networks. Let me explain this a bit more.
History of Deep Learning
We’ve got two main parts in neural networks: feedforward neural networks (FNNs) and recurrent neural networks (RNNs). What sets RNNs apart is their looped connections, making them great for tasks like speech and language processing.
This field has a rich history, going back to the 1920s when Wilhelm Lenz and Ernst Ising introduced the Ising model, a non-learning RNN. Fast forward to 1972, and Shun’ichi Amari jazzed it up, making it adaptable. This adaptable RNN got a popularity boost in 1982, thanks to John Hopfield.
Frank Rosenblatt. In his 1962 book, he introduced the multilayer perceptron (MLP), a key ingredient in today’s deep learning systems. His MLP model had a simple structure – an input layer, a hidden layer that didn’t learn, and a learning output layer.
The term “deep learning” itself was coined by Rina Dechter in 1986, but the concept evolved over time. Alexey Ivakhnenko and Lapa were pioneers, too, publishing the first learning algorithm for deep, feedforward, multilayer perceptrons in 1967.
Another breakthrough was Amari’s 1967 introduction of the first deep learning MLP trained by stochastic gradient descent. However, Matthew Brand pointed out in 1987 that training deep networks with many layers, like his 12-layer perceptron, was tough with the tech available then.
Enter Seppo Linnainmaa, who, in 1970, laid the groundwork for backpropagation – a game-changer for training neural networks. This technique was coined “back-propagating errors” by Rosenblatt in 1962 and later refined by others like Paul Werbos in 1982 and David E. Rumelhart in 1985.
The 1980s were buzzing with innovations. Kunihiko Fukushima’s Neocognitron, a precursor to CNNs, and his introduction of ReLU in 1969 set the stage for modern neural networks.
The concept of Deep Learning was furthered by Dechter in 1986 and Igor Aizenberg et al. in 2000. By 1988, Wei Zhang et al. were using backpropagation for CNNs in alphabet recognition, and in 1989, Yann LeCun’s team applied it to recognize handwritten ZIP codes.
Jürgen Schmidhuber’s work in the 1980s, including proposing a hierarchy of RNNs and linear Transformers in 1992, paved the way for today’s advancements.
Ashish Vaswani et al. brought us the modern Transformer in 2017, a major leap for NLP and computer vision. Schmidhuber also introduced adversarial neural networks in 1991, leading to the development of GANs.
The 1990s and 2000s saw continued progress. Sepp Hochreiter’s 1991 thesis on the vanishing gradient problem led to LSTM, a major advance in deep learning.
In 1994, André de Carvalho et al. explored multilayer boolean neural networks, and in 1995, Brendan Frey successfully trained a six-layer network using the wake-sleep algorithm.
Sven Behnke’s work since 1997 on the Neural Abstraction Pyramid expanded the reach of hierarchical convolutional approaches.
By 2003, LSTM began outperforming traditional methods in speech recognition, a trend solidified by 2015 when Google improved its speech recognition by 49% through LSTM trained by CTC.
In the early 2000s, CNNs were already processing a sizable chunk of US checks. Geoff Hinton and his team in 2006 demonstrated the effective pre-training of many-layered feedforward neural networks.
The 2009 NIPS Workshop spotlighted DNNs’ potential in speech recognition, setting the stage for the widespread adoption of these technologies in various fields.
What is deep learning?
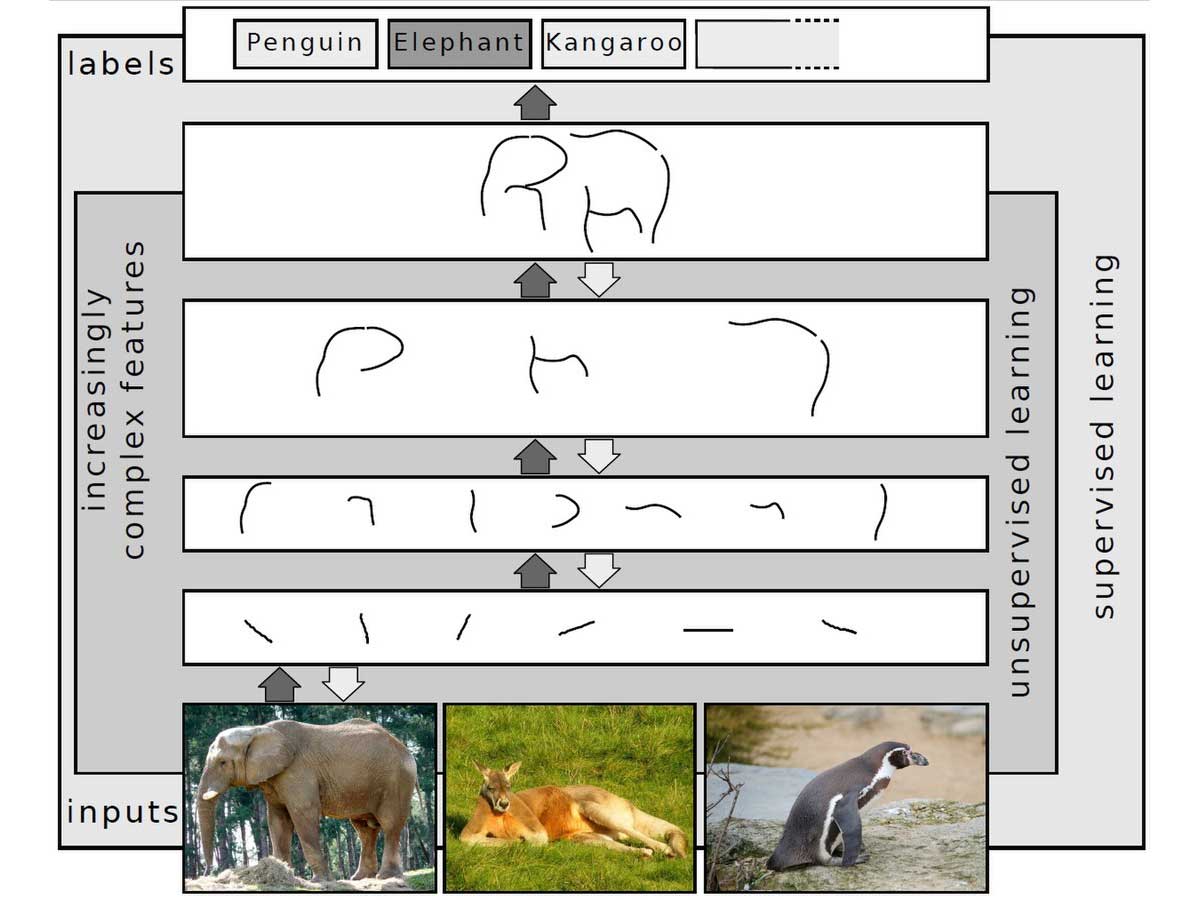
Deep learning is basically a subset of machine learning, which is essentially a neural network with three or more layers, including the input and output layers. To further explain, we can say deep learning is a type of machine learning and artificial intelligence (AI) that copy the way we as humans learn and gain certain types of knowledge.
It’s like when you learn to recognize a cat in a photo, and deep learning algorithms help computers do the same thing! These intelligent systems are great at classification tasks. They can spot patterns in photos, text, audio, and all sorts of various data.

The cool thing about deep learning is that it’s like giving a computer a bit of our brainpower. It helps with jobs that usually need human intelligence, like describing pictures or turning spoken words into text.
This technology is important, especially in data science, where it mixes with statistics and predictive modeling to help data scientists make sense of tons of info.
Our brains have loads of neurons that connect and learn together. Deep learning uses something similar called neural networks. These are layers upon layers of software nodes that team up to process information. To train these models, you need a big bunch of labeled data and neural network architectures.
Deep learning algorithms are behind a lot of everyday products and services that we use, like digital assistants, voice-enabled TV remotes, and credit card fraud detection, to self-driving cars.
Deep learning vs. machine learning
When we talk about machine learning Vs. deep learning, You might think, what’s the difference between those two?
Deep learning is a special part of machine learning; I mentioned it earlier in the article. But they’ve got their own ways of doing things.
Traditional machine learning algorithms mainly use structured, labeled data. You’ve got to pick out specific features from this large amount of data and line them up neatly in tables.
Sure, machine learning can handle messy, unstructured data like text and images, but it needs some cleaning and organizing first.
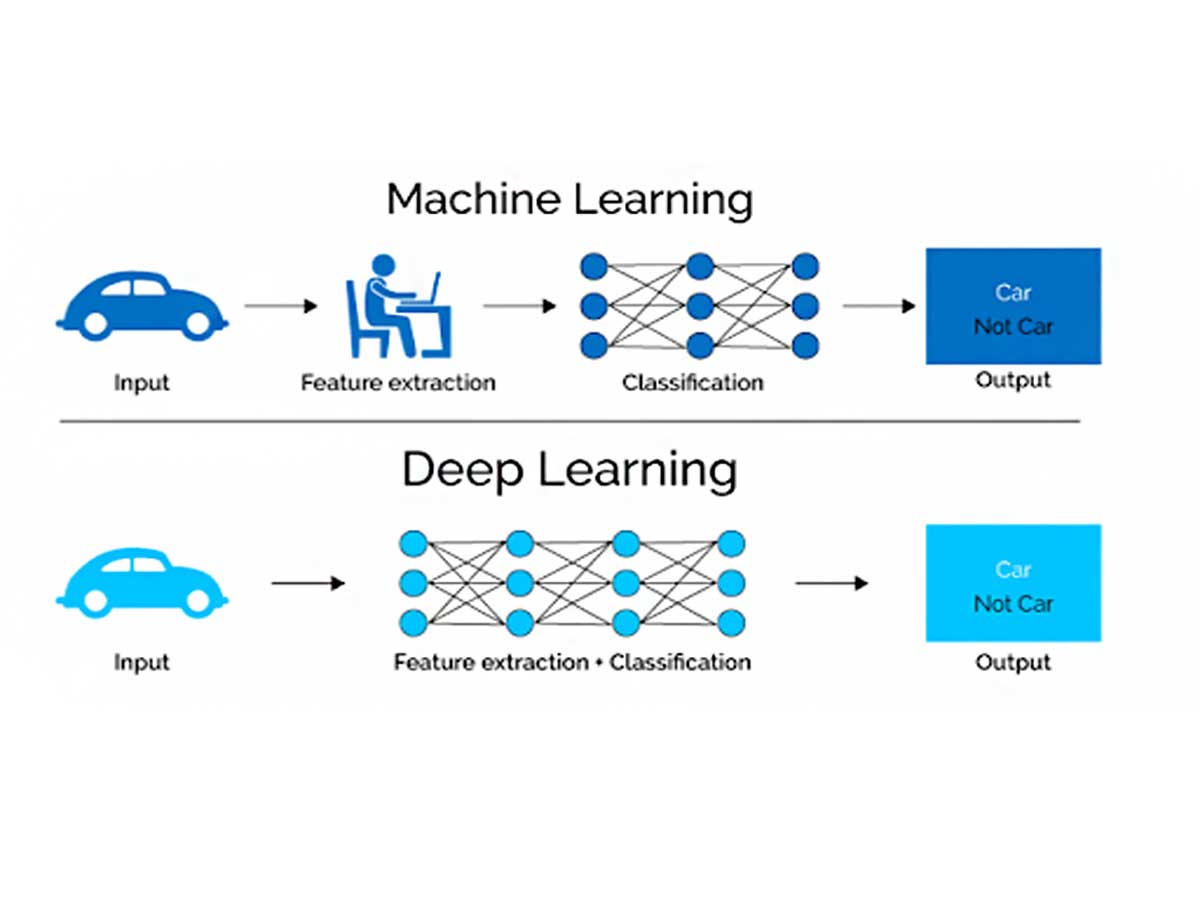
Now, deep learning consumes unstructured data without needing much pre-processing. And it automates feature extraction. So, instead of needing a human expert to tell the system what to look for in a photo of a pet, deep learning figures it out by itself.
Deep learning tweaks itself for better accuracy using techniques like gradient descent and backpropagation. This means it gets really good at making sharp predictions for new photos.
Both machine learning and deep learning have their own styles of learning, too. There’s supervised learning, where you train the system with labeled datasets.
This needs a human intervention touch to make sure the labels are right. Then there’s unsupervised learning, which is like letting the system decide, finding patterns, and clustering data based on different features, all without needing labeled data.
And let’s not forget reinforcement learning, where the model learns through trial and error, aiming to maximize rewards.
Is deep learning important?
Think of deep learning programs like a super-smart toddler; why just humor me? You’ll understand at the end. Just like a little kid learning to point out a dog, these programs get better at identifying stuff in the world around them.
They’re built with multiple layers of nodes(three or more), all linked up. Each layer is making the program smarter and sharper at guessing what it’s looking at.
These layers have nonlinear transformations on all the data they get. The end goal is to make a statistical model that makes sense of this mess of data. These programs need a few tries or iterations to get things right.
The “deep” in deep learning comes from the number of processing layers the data goes through. It’s a deeper dive than traditional machine learning, where you have to tell the computer exactly what to look for. But deep learning algorithms figure this out on their own; no hand-holding is needed.
To understand this, let’s take a picture of a dog. When starting out, these programs might get a bit of help with some training data, like photos tagged ‘dog’ or ‘not dog.’ Using these tags, the program starts to understand what makes a dog a dog.
It might begin with simple concepts like anything with four legs and a tail in a photo is probably a dog. But It’s looking at the pixels, the tiny dots of color, and learning the patterns.
Over time, deep learning algorithms can go through millions of photos (massive amounts of data) and spot dogs faster. And to get this level, they need a large amount of data and some serious computer power. That’s where big data and cloud computing come into play.
What’s really awesome about use deep learning is that it doesn’t just work with neatly labeled data. It can take a heap of messy, unorganized info and still make sense of it, creating complex statistical models.
Deep learning neural networks
Deep learning neural networks, also known as artificial neural networks, are like techy twins of the human brain. These programs use data inputs, weights, and biases to accurately recognize, classify, and describe objects within the data.

These interconnected nodes are in multiple layers – that’s what makes up these networks. Each layer is like a step up, making the network better at guessing or sorting data.
They go through a process called forward propagation, where the network works on numbers and makes sense of the data. In these networks, the input and output layers are the big players. The input layer consumes data for processing, and the output layer gives you the final answer.

But what if the network gets it wrong? That’s where backpropagation comes in. It’s a smart algorithmic mechanism using things like gradient descent to find mistakes in the predictions.
It then goes backward through the layers, tweaking weights and biases to get better next time. This back-and-forth dance between forward propagation and backpropagation is what makes these networks super accurate over time.
There are different kinds of Neural networks for different jobs.
- Convolutional neural networks (CNNs)
- Recurrent neural networks (RNNs),
- ANNs and feed
- Forward neural networks as well.
Deep neural network (DNN)
Deep neural network” and “deep learning neural networks” are terms that are closely related but can have subtly different meanings depending on the context
A deep neural network (DNN) is a machine learning algorithm miming the brain’s information processing and learning process. DNNs are similar to artificial neural networks (ANNs).
They have multiple layers of nodes that act like neurons in the brain. The weights of these neurons are fed into other layers of neurons, which then assign weights and pass them on.
This is also an important part of AI and machine learning. And even when machine learning models.
Deep learning methods
Several approaches can be employed to develop robust deep learning models. These methods contain learning rate reduction, transfer learning, starting from the ground up, and dropout.
Learning rate decay: It’s all about the learning rate, a key hyperparameter that controls how much a model changes in response to the estimated error. Get the rate too high, and your model results in unstable training processes or the learning of a suboptimal set of weights.
Too small may produce a lengthy training process that has the potential to get stuck. Learning rate decay, also known as annealing or adaptive learning rate, is the art of slowly reducing this rate over time.
Transfer learning: This process involves perfecting a previously trained model; it requires an interface to the internals of a preexisting network. First, users feed the existing network new data containing previously unknown classifications.
Once adjustments are made to the network, new tasks can be performed with more specific categorizing abilities. This method has the advantage of requiring much less data than others, thus reducing computation time to minutes or hours.
Training from scratch: This is for dealing with new applications or having a ton of categories to sort through. You’ll need a big pile of labeled data and a bit of patience, as it takes days or even weeks to train.
Dropout: This is the AI version of a reality check for models that might be too smart for their own good. It randomly drops out units and connections during training to prevent overfitting. This technique has shown great results in areas like speech recognition, document classification, and even computational biology.
Deep learning applications
Deep learning applications transforming the way we do things without us even realizing it. They’re woven into products and services, making complex data processing easy.
- Law enforcement: Here, deep learning dives into transactional data, sniffing out dangerous patterns and potential fraudulent or criminal activities. It uses tools like speech recognition and computer vision to boost the efficiency and effectiveness of investigations.
- Financial services: Uses predictive analytics for algorithmic stock trading, assessing risks for loan approvals, spotting fraud, and even managing credit and investment portfolios.
- Customer service: This is where deep learning has brought chatbots to life. These bots can handle our queries, even the vague ones. They use natural language and visual recognition to chat with us, routing more problematic conversations to human experts.
- Virtual assistants: Apple’s Siri, Amazon Alexa, or Google Assistant take this to the next level. They extend the chatbot idea with speech recognition, creating personalized experiences for us.

- Healthcare: deep learning is making waves since digitizing hospital records and images. It supports medical imaging specialists and radiologists, speeding up the analysis and assessment of images.
- Industrial automation: Deep learning enhances worker safety in settings such as factories and warehouses by offering industrial automation services that can autonomously identify instances when a worker or object approaches dangerously close to a machine.

- Color enhancement: Deep learning models can introduce color to black-and-white photographs and videos.
- Computer vision: Deep learning has significantly improved computer vision capabilities, enabling computers to achieve exceptional precision in tasks such as detecting objects, image recognition, restoring images, and segmenting images.
What is Natural language processing (NLP)
Natural language processing (NLP) is like a bridge between humans and computers.
It’s a branch of artificial intelligence that helps computers get what we’re saying, interpret it, and even talk back! NLP has some subfields, like Natural language understanding (NLU) and Natural language generation (NLG).
NLU digs into semantic analysis, striving to figure out the actual meaning behind the words we use. Meanwhile, NLG is all about getting machines to create text on their own.
NLP has some techniques involved in doing this. One of them is lemmatization, where a word is peeled back to its root meaning, helping the system spot similarities between words.
Part-of-speech tagging is like labeling each word in a sentence – noun, verb, adjective, you name it – so the computer understands the role each word plays.
Sentiment analysis, where the computer figures out if the words have a positive vibe, a negative tone, or are just neutral.
Deep learning systems: Limitations and challenges
Deep learning systems are pretty amazing, but they’re not without their hiccups and hurdles. One big thing is they learn by looking at stuff, kinda like how we do. But they’re totally dependent on the data they’re trained with. If the data is not diverse or big enough, the learning is kind of limited.
Then, there’s the issue of biases in deep learning models. These systems can accidentally pick up biases from their training data. It’s tricky to figure out why they make certain decisions, and sometimes, they can end up with biases we didn’t intend, like those based on race or gender.
Hardware requirements are no joke, either. We’re talking serious computing power, like multicore GPUs that are both pricey and hungry for energy. Plus, you need a good amount of RAM and either a hefty hard disk drive or a speedy RAM-based SSD.
There are a few more limitations and challenges to keep in mind. For starters, large data requirements. The more complex the model, the more data and parameters it needs. Also, deep learning models aren’t great multitaskers.
Once they’re trained for one thing, they can’t just switch to something else without retraining. And when it comes to lack of reasoning. Handling reasoning tasks is not one of the uses of deep learning algorithms; long-term planning and algorithmic data manipulation are still beyond their reach, even with a large amount of data.